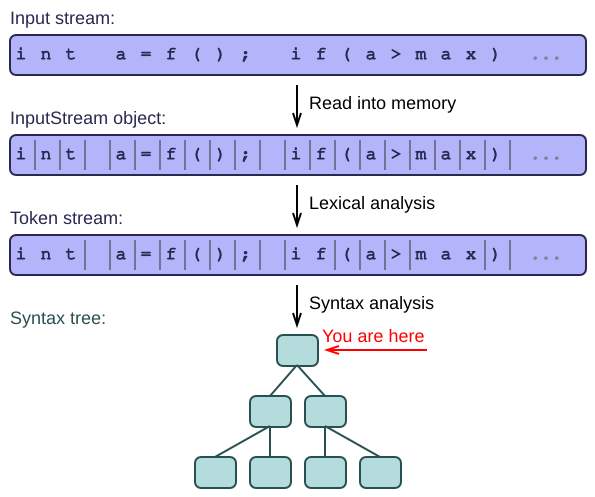
- The lexer groups the input characters into tokens. After that, syntax functions read such tokens and create syntax nodes from them. The nodes are stored in a tree.
- When it fails, a syntax function must backtrack to a previous input position, and undo any side effects it caused while parsing.
- When it encounters a syntax error, the function should report the error, should not backtrack, and could even try to continue parsing (to uncover even more errors).
How to parse by hand
- So far, we have an InputStream with coordinates and backtracking, and a lexer that groups input characters into tokens.
- We now take the next step: We write the actual parser, which turns the tokens into the final tree structure. The tree is composed of nodes, which are linked to each other by parent-child references.
Some terminology
Parsing is also known as syntax analysis (as opposed to the lexical analysis of the previous article). It won't surprise you that the tree structure created by the parser is often called a syntax tree.
You may also bump into the term concrete syntax tree, which is a tree that contains all the tokens at its leaves. By printing the leaves of such a tree in depth-first order, you get the original input text back again. Most applications have no use for this, so they often remove the tokens and keep only the nodes and their structural relations. This is called an abstract syntax tree.
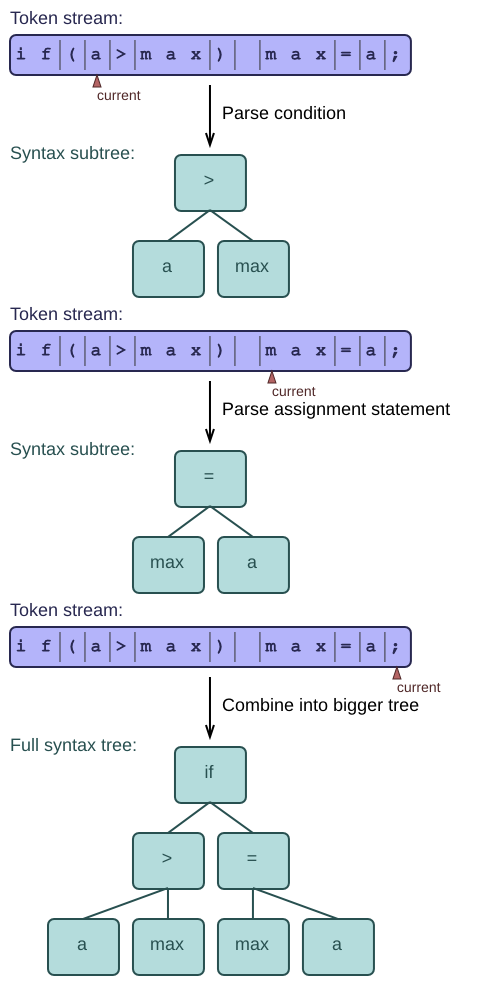
The goal of a syntax function is to take a small subsequence of the tokens and turn it into a single subtree of the total syntax tree. The node at the very top is created by the "main" syntax function, which calls the other functions recursively and combines their results into one large tree. This strategy is called recursive descent.
Syntax functions or syntax methods?
The syntax functions can be implemented in a number of different ways:
- They are typically member functions of a Parser class. The class has a pointer to a lexer, or could even inherit from Lexer so that it has easy access to the tokens or even to the underlying input stream. Having all the syntax functions together in a single class, makes it easy to inherit one parser from another, so you can extend an existing input language with new syntax.
- You could also implement the syntax functions as non-member functions, each taking a parser as an argument. You can then make a parser class that simply stores a list of pointers to such functions, which it calls in the specified order. It returns the structure produced by the first function that succeeds. By putting different sets of functions in this list, and changing the order in which they are invoked, you can very flexibly change the syntax of your input language, or assemble a parser from existing parts.
- With schema-based parsing, as explained in a later article, we will collect a number of node classes into a schema. Each node in the syntax tree is an instance of such a class. We can then implement the parser functions as static factory methods of the node classes. Each of those factory methods creates a subtree by parsing the top node from the input.
To focus the explanation, we will use the first approach here: we implement our examples as member functions of a Parser class, which holds a Lexer member. That way, all the responsibilities are nicely separated. In addition, we assume that we always parse from a file, rather than a string or other input stream. So we will implement all syntax functions as methods of this class:
code_cxx/prs.cc
1 // Turns a stream of tokens (from the lexer) into a tree structure. 2 // Uses recursive calls of syntax methods to create the tree top-down. 3 // This is known as "recursive descent parsing" and is the easiest 4 // technique for hand-written parsers. 5 class Parser { 6 private: 7 Lexer* m_lexer; 8 9 public: 10 Parser(const char* filename) { 11 m_lexer= new Lexer(filename); 12 } 13 14 virtual ~Parser() { 15 delete m_lexer; 16 } 17 18 // ... 19 };
Some simple rules to follow
Writing a syntax function by hand is not very difficult if you keep a few simple rules in mind:
- Either the syntax function succeeds, returning the top node of a new subtree. It skips all input tokens which were consumed while creating the subtree. The next function can then start parsing the next tokens immediately.
- Or the function fails, returning a "null" node. In this case, it must not skip any tokens, so that another function can have a go at parsing the same input. And, equally importantly, the function must not have any side effects: it must not create any objects, enter any symbols into a symbol table, or produce any other changes in the parser's internal state.
Sounds familiar? You're right: these rules are very similar to the ones we discussed for lexing. Lexing produces tokens, and parsing produces structures. Other than that, they are very similar processes.
As an exercise, you could verify that the code samples below obey our set of rules.
Some examples in C++
OK, enough talking, time for some code! We now write some syntax functions by hand. We will abstract them into grammar rules later, but it is important to understand how things work under the hood first.
Suppose we want to parse a function call: an identifier followed by a parenthesized list of arguments. For simplicity, we assume that all the arguments are in turn function calls, so that we can use the same parsing code for the call and its arguments.
Our syntax function needs to turn the input stream into a structure. So we just make it return a pointer to an instance of the following class:
code_cxx/prs.cc
1 struct FunctionCall { 2 string m_name; 3 list<FunctionCall*> m_arguments; 4 };
If we fail to find the required tokens in the input, we simply return a NULL pointer to indicate failure.
The syntax function uses the lex functions we described earlier. Here is its code in full splendor:
code_cxx/prs.cc
1 FunctionCall* Parser::parse_function_call() { 2 Coord start= m_lexer->getCoord(); // Remember our position for backtracking. 3 4 // Try to parse the function name. 5 m_lexer->parse_white_space(); 6 string name= m_lexer->parse_identifier(); 7 if(name == "") 8 return NULL; // Fail by returning a NULL pointer. 9 10 // Now look for the opening '(' of the call. 11 m_lexer->parse_white_space(); 12 if(m_lexer->getChar() != '(') { 13 m_lexer->setCoord(start); // Backtrack to original position! 14 return NULL; // Fail by returning a NULL pointer. 15 } 16 17 // Create the resulting node instance. 18 // From now on, we can't fail anymore! 19 FunctionCall* result= new FunctionCall; 20 21 // Fill the structure with the data we have so far (i.e. the function name). 22 result->m_name= name; 23 24 // Now parse the arguments, separated by a comma. 25 char separator= ','; 26 while(true) { 27 // Each argument is in turn a function call. 28 // We call 'parse_function_call' recursively, 29 // hence the name "recursive descent parsing". 30 FunctionCall* arg= parse_function_call(); // This also skips white space. 31 if(!arg) 32 break; // No more arguments => stop the loop. 33 34 // Store the parsed argument as a subtree of our FunctionCall tree. 35 result->m_arguments.push_back(arg); 36 37 // Find a separator between the arguments. 38 m_lexer->parse_white_space(); 39 if(m_lexer->peekChar() != separator) 40 break; 41 42 m_lexer->getChar(); // Skip the separator (we only peeked it). 43 } 44 45 // After the arguments, find the closing ')'. 46 m_lexer->parse_white_space(); 47 if(m_lexer->getChar() != ')') { 48 // Syntax error: Missing ')'. Do NOT fail! 49 } 50 51 return result; 52 }
The function creates the resulting structure only after it has seen the opening parenthesis. Without this parenthesis, we can be sure that whatever we found in the input is not a function call (perhaps it's a variable name or some other identifier). So we can just backtrack and return NULL. But as soon as we have seen the parenthesis, we can safely assume that we are looking at a function call, so we create the resulting object and start filling it. The creation of this object is a side-effect, so we have to be very careful after this point: If we fail, we have to delete the object (if you're a seasoned C++ programmer, you will use smart pointers for extra safety). Alternatively, we can agree that we never fail once the object is created. Any problematic input after this point will lead us to report a syntax error rather than silently backtrack.
This example employs the easiest technique for hand-written parsers, known as recursive descent parsing. The name reveals that the syntax functions call each other recursively, and that they create the top node of the tree first, descending to the leaves:
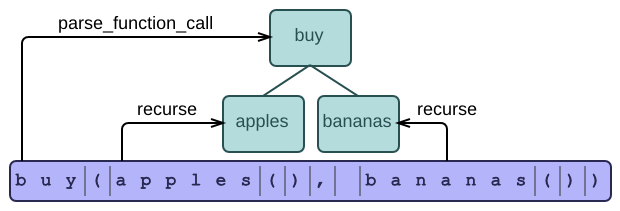
Note that we do not handle errors yet. For example, our syntax function does not complain when a comma is not followed by an argument. It happily parses incorrect input like the following:
1 f(g(), h(), )
We may look at error handling in a later article. Here I just want to focus on the main parsing process.
Now that we have a way of parsing expressions (at least nested function calls), we can start using these expressions to parse statements, such as an assignment statement:
code_cxx/prs.cc
1 struct AssignmentStatement : public Statement { 2 string m_variableName; 3 FunctionCall* m_value; 4 }; 5 6 AssignmentStatement* Parser::parse_assignment_statement() { 7 Coord start= m_lexer->getCoord(); // Remember our position for backtracking. 8 9 // First, look for the name of the variable 10 // on the left-hand-side of the assignment. 11 m_lexer->parse_white_space(); 12 string variableName= m_lexer->parse_identifier(); 13 if(variableName == "") { 14 // No variable name => no assignment statement. 15 return NULL; 16 } 17 18 // Now look for the assignment operator. 19 // In a more robust parser, we would verify that this is not 20 // some other operator like '=>'. 21 m_lexer->parse_white_space(); 22 if(m_lexer->peekChar() != '=') { 23 m_lexer->setCoord(start); // Backtrack, to put the identifier back in the input. 24 return NULL; 25 } 26 m_lexer->getChar(); // Skip the '=' (we only peeked it). 27 28 // At this point, we *know* that we have an assignment statement. 29 // We create the object, and agree not to fail anymore beyond this point. 30 AssignmentStatement* result= new AssignmentStatement; 31 result->m_variableName= variableName; 32 33 // Now parse the right-hand-side expression (just call the other syntax function). 34 result->m_value= parse_function_call(); // Also takes care of leading white space. 35 if(!result->m_value) { 36 // Syntax error: Missing expression. Do NOT fail! 37 } 38 39 // Now look for the semicolon that terminates the statement. 40 m_lexer->parse_white_space(); 41 if(m_lexer->peekChar() != ';') { 42 // Syntax error: Missing ';'. Do NOT fail! 43 } 44 m_lexer->getChar(); // Skip the ';' (we only peeked it). 45 46 return result; 47 }
The comments in the code should explain everything.
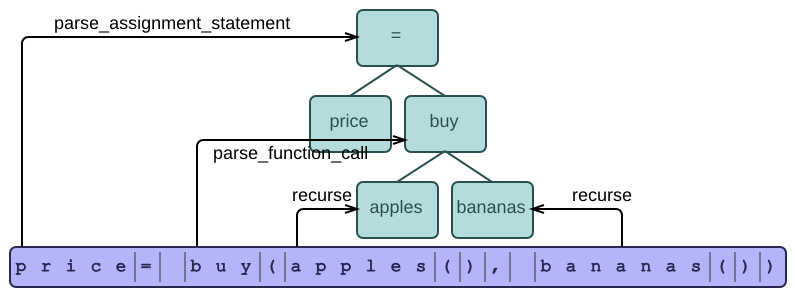
Our final example offers a good summary of the rules for syntax functions. Suppose our language has assignment statements, if-statements, and many other kinds of statements. They all inherit from a common Statement class. All we have to do is try each of the possibilities in turn:
code_cxx/prs.cc
1 Statement* Parser::parse_statement() { 2 // First try an 'if' statement. It takes care of white space, 3 // so we don't have to worry about that here. 4 IfStatement* st1 = parse_if_statement(); 5 if(st1) return st1; 6 7 // If the 'if' fails, it leaves the input unchanged (because it follows 8 // the rules of good parsing behavior), so we can simply try the assignment 9 // statement right after it. 10 AssignmentStatement* st2 = parse_assignment_statement(); 11 if(st2) return st2; 12 13 // ... (try other kinds of statements next) 14 15 // The attempt at parsing any kind of statement failed. 16 // They all left the input unchanged. We now fail in turn, 17 // leaving everything unchanged and returning NULL. 18 return NULL; 19 }
By being well-behaved, our syntax functions can very easily be combined into a bigger whole.
Backtracking
When a syntax function fails, we want it to have no side effects. We want the input to be exactly the way it was before calling the function, because this makes it easier for other functions to have a go at parsing the same input. In addition, the function should delete any objects that it created, remove any symbols it entered into a symbol table, etc. In other words, the function has to backtrack to an earlier situation.
So far, we've only seen examples of backtracking in an inpuit stream: By calling setCoord, we move the input pointer back to a previously stored position. The ANTLR tool, which I may write about in a future article, generates syntax functions with a similar backtracking mechanism:
1 int _m15 = mark(); // Remember input location. 2 // ... try matching input 3 rewind(_m15); // If matching fails, backtrack to earlier location.
We won't talk about the symbol table in this series of articles, but I should mention that the syntax function, when backtracking, also has to forget any symbols it created while parsing. The Schol framework has built-in support for this; other tools require the developer to take care of it explicitly.
The syntax function also has to delete any objects it created. It is therefore best not to store these objects in global data structures until after the successful completion of the entire syntax function.
In general, all the actions that a syntax function executes, must be "reversible", and must be undone when backtracking. In our earlier examples, syntax errors do not cause backtracking. The errors are simply reported, but we keep trying to parse the rest of the node. We return the (partial, incorrect) subtree to the caller, so technically we do not fail and do not have to backtrack. The point where you decide to stop failing and start complaining, is the point where you are sure about what you are parsing. You know what should come next in the input, so you're allowed to complain when you don't find it.