- In this article, we automate the creation of the syntax tree.
- In a schema, we describe the classes for all nodes in the tree. Each class has its own abstract syntax rule, which refers to the member variables of the class. The types of these members provide useful information for the parser: it knows which functions to recurse to, without our help.
- The meta-parser has to parse the entire schema, including the class definitions and their members. This can be a lot more work than parsing a traditional grammar.
- Once we have a schema, we can extend it with many additional features. Schemas are a good investment, because they can become the centerpiece of a very powerful, feature-rich parsing framework.
Schemas and syntax trees
- We started from hand-written, top-down, recursive-descent parsers. We then condensed their syntax functions into very compact syntax expressions, collecting those into a grammar called a PEG. From the grammar, the original syntax functions can be generated.
- We now take the next step: the creation of the syntax tree. We could do this by attaching actions to the grammar rules. When matched, a rule executes its action, which in turn creates the nodes of the tree.
- But we can do better: We can make the creation of the tree nodes fully automatic by exploiting the information already available in the node classes.
Ambitious goals
After all the high-up-in-the-clouds theory of the previous article, let's get our feet back on solid ground. We want to combine the best practices of earlier articles into a new approach, based on schemas. Our goals are ambitious:
- We don't want to write syntax functions by hand. Instead, we want to write simple syntax rules, and use a tool to convert those into lower-level code. Alternatively, our tool could interpret the rules and execute them "live", without generating code first.
- We don't want our grammar to be polluted with artifacts. No left-factoring, no unordered ambiguity, no unwanted complexities. In other words: we will be using PEGs, not declarative grammars.
- We want to give an object-oriented description of the syntax tree, and attach our syntax rules to that description. The tool should not only recognize the input, but create the entire tree fully automatically.
These ambitious goals are going to require a novel, alternative approach. We now leave the official path and head for new territory.
Creating a syntax tree by using actions
For a moment, think back about our earlier, hand-written recursive-descent parser. It fetched a number of tokens from the input stream, and then at some point it decided to create a syntax node. Each node was an instance of some hand-written class such as FunctionCall or IfStatement. The parser then fills the member variables of the node with information from the input stream (e.g. the name of the FunctionCall is fetched from an Identifier token in the input).
From those hand-written parsers, we then developed much more compact syntax expressions (also dubbed syntax rules). We collected them into a grammar, and we discussed various possible grammar formalisms, each with its own pros and cons. Invariably, these formalisms required us to attach actions to the grammar rules, in order to make the rules do something useful.
For example, the following snippet of grammar (written in an imaginary parsing framework) would create a new node of class NamespaceStatement, fill in its name, and create child nodes of class Statement:
1 // The classes from which we want to instantiate nodes. 2 class Statement { 3 }; 4 5 class NamespaceStatement : Statement { 6 public: 7 string name = ""; // Name of the namespace. 8 List<Statement> body_statement; // Statements in namespace body. 9 }; 10 11 // The grammar which creates the nodes. 12 namespace -> "namespace" identifier "{" statement* "}" ";"? 13 { 14 // This is the action attached to the 'namespace' rule. 15 // It creates the node and returns it to the caller. 16 // It also links the child statements into a subtree. 17 NamespaceStatement* node= new NamespaceStatement; 18 19 // Transfer parsed tokens to the node members. 20 node->set_name(identifier); 21 for(Statement* st : statement) { 22 node->add_body_statement(st); 23 st->link(node); 24 } 25 return node; 26 }
This may seem like a clean, simple implementation. But the truth is that it contains a lot of redundant effort. We have to explicitly state that we're creating a NamespaceStatement, and we have to explicitly transfer information from the input stream to the new node (e.g. copying the identifier token into the name member). We have to repeat this effort for all the classes in our library (such as IfStatement, WhileStatement, and dozens of other node classes). We're not making any use of the information which is already present in that library.
We can do better than that.
Creating a syntax tree by using a schema
Since we already have a collection of node classes with member variables, why not write our syntax rules inside those classes? That way, the parser already knows which node class to instantiate, so we don't have to repeat that information in the attached action.
The next step is to realize that we can make clever use of the names and types of our member variables. For example, when invoking the identifier rule, we could simply specify the name of the data member to which this identifier must be transferred. And when recursing to the Statement rule, it is sufficient to say that we want to parse the body_statements member of our node, because the parser can already see in the node class that this is a list of Statement nodes!
This way, we can make the parser fill the member variables automatically. All the information is already available; we just have to hook it together. The result is a collection of syntax-aware classes called a schema.
From such a schema, we could either generate the syntax functions (leading to a very fast, tightly integrated parser), or we could interpret the syntax rules in a more dynamic language (making the parser slower but more flexible). The Schol framework [1] uses the first approach. In this article, we will look at an example of the second approach, using reflection in C#.
[1] I intend to describe the Schol parsing framework in a future article.
An example in C#
Let's begin with a very modest base class from which all node classes will inherit. It just stores the parent/child relations of the syntax tree, and the starting coordinates of each node (so that we can produce debug messages that refer to the exact location in the original input file).
1 public class SyntaxNode 2 { 3 public int lin = 0; 4 public int col = 0; 5 public SyntaxNode parent = null; 6 7 public void link(SyntaxNode other) 8 { 9 parent = other; 10 } 11 12 public void unlink() 13 { 14 parent = null; 15 } 16 }
I know, I know, public member variables are Evil. I just want to make the examples as simple as possible, so I won't bother to follow all the rules of good behavior. Let's quickly move on to our first node class. It's called NamespaceStatement, and it should be the result of parsing a (possibly nested) namespace in some programming language like C++ or C#. In its simplest form, the class looks like this:
1 public class NamespaceStatement : Statement 2 { 3 public string name = ""; 4 public List<Statement> statements = new List<Statement>(); 5 }
We need only 2 member variables: one for the name of the namespace, the other for its body, which is basically a list of statements (typically class definitions, function declarations and other such statements). Since C# is a statically typed language, we can be very precise about the types of these member variables; this will turn out to be crucial for the correct working of our parser.
The parser will read a namespace from the input, and create the corresponding node:
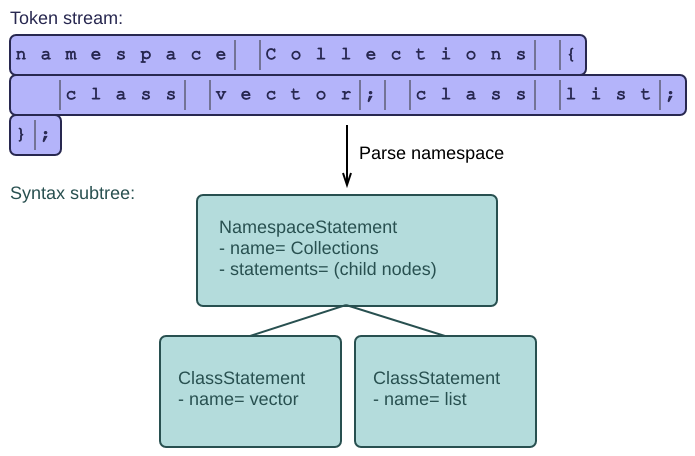
Okay, we're ready to add the syntax rule now. In C#, it's very easy to use attributes for this purpose. Attributes are a kind of meta-information that you can stick to a class or its members. Assuming that we've already defined the Syntax attribute somewhere, we use it as follows:
1 [Syntax("'namespace' => name:qualified_name '{' statements* '}' ';'?")] 2 public class NamespaceStatement : Statement 3 { 4 public string name = ""; 5 public List<Statement> statements = new List<Statement>(); 6 }
The class is still the same, but now it has a Syntax attribute attached to it, which tells the parser how to parse a NamespaceStatement. From the syntax rule, the parser figures out that it needs to perform the following steps:
- Store the current coordinate for backtracking.
- Find the keyword 'namespace' in the input. If not found, simply return a null reference. Backtrack to the stored coordinate, so that another syntax function can have a go. This is just the good old contract we want our functions to obey.
-
After the keyword is found, we can safely assume that we're parsing a
NamespaceStatement, so we create the node. After this point, we will never backtrack across the 'namespace' keyword again. The creation of the node is a side-effect that we will never undo; if something goes wrong, we produce an error and let the user know that the input is faulty, rather than silently backtracking.-
The double arrow '=>' is our way of explicitly marking this point of no return. The parser follows this arrow only from left to right, never back. The arrow allows the parser to instantiate the
NamespaceStatementclass.
-
The double arrow '=>' is our way of explicitly marking this point of no return. The parser follows this arrow only from left to right, never back. The arrow allows the parser to instantiate the
- After this, we silently parse white space (remember that most frameworks do this automatically, and it makes our lives a lot easier).
-
Next, we parse the name of the namespace. Note that the syntax rule refers to the
namemember of the class, so it automatically knows that it should parse some kind of string. We can be more specific and tell the parser to look for aqualified_name, which is a lex rule that reads names such as 'A.B.C'. The result is stored directly in thenamemember of our brand new node. -
We parse the opening brace, and then a list of statements. Again, this refers to the
statementsmember of the class, so the parser already knows that it needs to parse a list of statements! We no longer have to make a recursive call to some 'parseStatement' function, because this is already implied by the type of the member. We only need a simple '*' to indicate that the list can contain 0 or more nodes. The parser will collect the nodes returned by the recursive calls, and store them in thestatementsmember of our new node. - Finally, the parser reads the closing brace and an optional semicolon, and it returns the created node.
This is a very compact, clean representation of a grammar which includes the full description of the syntax tree. The tree grows top-down: The top class has a syntax rule which invokes other rules, collects the resulting nodes, and stores those in the member variables of the top node.
You may have noticed that our class inherits from Statement. That's just another class in our schema, which serves as a base class for all statements. It's also the type for the list of statements of the namespace, so we're still making heavy use of recursion here. The Statement base class is empty, but it does have a syntax rule attached to it:
1 [Syntax("IfStatement|WhileStatement|ForeachStatement" 2 + ... // Many statements omitted 3 + "NamespaceStatement|ClassStatement|EnumStatement" 4 + ... // Many statements omitted 5 )] 6 public class Statement : SyntaxNode 7 { 8 }
This basically tells the parser: If you're asked to parse a Statement node, just try all the alternatives in the given order, and return the result of the first one that succeeds. The alternatives are tried strictly in the given order, because we want our parser to behave like a hand-written one (or like a PEG). Note that this class inherits from SyntaxNode, the top of the class hierarchy we implemented earlier.
On meta-parsers and code generators
In our earlier excursions into syntax rules and grammars, I have forgotten (on purpose) to talk about the meta-parser. This is the piece of code that parses the syntax rules, from which the syntax functions are generated. That's right: there are really two parsers involved in our story. We've been focusing on the parser we develop for creating the final syntax tree. But somebody has to parse the abstract syntax rules first!
We have ignored this topic until now, but we can't any longer. When working with schemas, the meta-parser becomes a lot more elaborate than before. Instead of parsing only syntax rules, it now also has to parse class definitions containing typed member variables. This can be a lot more work, making the code generator much more difficult to write and maintain.
In the case of our C# example we are lucky: C# has a powerful reflection mechanism, which allows us to obtain a list of classes, their members, their types, and even the attributes attached to them. So we can get a hand on all the required information without having to write a meta-parser: C# already does that for us.
Other frameworks like Antlr and Schol require a more advanced meta-parser. We've already seen a lot of techniques for parsing, and any of those could be used for developing the meta-parser. Note that this has to be done only once: The meta-parser is published as part of the framework, and will then assist in creating thousands of other parsers for us.
After bootstrapping such a meta-parser for the first time (by writing it by hand, or by generating it using some other existing tool), you can usually implement the second version within your parsing framework itself. The meta-parser uses a meta-schema with classes such as SyntaxRule and ClassDefinition, from which it can parse schemas! One of those schemas is the meta-schema itself, so we can close the circle. This makes the parsing framework self-hosting. It usually does not require a lot of effort to reach this state.
Extra features
We have a schema with classes, member variables, and attributes. Each class has its own syntax rule, which exploits the member types to create the nodes automatically.
We can now add a lot of extra functionality on top of this, sometimes with huge added value. Here are just a few hints of what is possible.
-
We can give our class an extra attribute that tells the tool how to format an object of that class. When dumping the syntax tree to a log file for debugging, the tool can then simply execute this "formatting rule" for each node. The rule again refers to the member variables of the node. The required indentation is automatically deduced from the depth in the tree. Here's our earlier example in C#:
1 [Syntax("'namespace' => name:qualified_name '{' statements* '}' ';'?")] 2 [Format("@ name ; statements")] 3 public class NamespaceStatement : Statement 4 { 5 public string name = ""; 6 public List<Statement> statements = new List<Statement>(); 7 }
The '@' causes the tool to dump the class name of the node and its coordinates. The ';' causes a newline to be printed. Other than that, we just give the names of our member variables, and we're done. This is much, much shorter than writing a formatting function by hand.
- We can implement member functions in our schema classes. These could perform various tasks such as searching for a specific offspring node, transforming the node into another structure, or providing semantic information such as symbol table lookups. This is similar to attaching "actions" to the node classes, but now we can just use established object-oriented techniques, including inheritance and polymorphism (and even generics).
- We can specify semantic invariants for each class. This allows the parser to perform various sanity checks on the tree after creating it.
Pros and cons
I see a few downsides to the schema-based approach. Some of these can be circumvented, others just have to be accepted as part of a trade-off.
- Schema-based parsers always create a syntax tree. This is less flexible than other formalisms, which allow you to write an interpreter, recognizer or other tool by attaching actions directly to grammar rules. In practice, most of these tools will require a syntax tree anyway, so we may as well make the creation of such a tree as easy as possible.
-
The meta-parser is much more elaborate than for other formalisms. It needs to parse the full schema, including classes, types, member variables, and possibly even member functions and namespaces. This comes close to parsing a full programming language rather than just a domain-specific language for syntax rules.
- The C# example uses reflection to side-step this issue. It is extremely compact and can basically be distributed as a few C# files. It is slower than a generated parser though.
- A code generator needs to be made part of your build process. Generated code can be extremely fast, but it takes more effort to produce (it must be integrated as a build step in your makefiles).
For these inconveniences, we get a lot of compensation. Schemas are in a league of their own when it comes to writing fast, compact, highly maintainable and very powerful parsers.
- We no longer need to create the syntax tree by hand. The tool creates it automatically, and does not require any additional information from us. All the required knowledge is already part of the schema.
- The grammar is no longer polluted with irrelevant details. Instead of focusing on left-factoring and ambiguities, we now focus on the syntax tree and its clients.
- The schema describes the end result (the syntax tree) rather than the intermediate steps (the parser). The syntax tree is the single most important data structure in any language system. And yet, few existing tools allow you to describe it at a high level.
- You can easily add extra functionality to the schema, such as formatting the tree for debugging, symbol table lookup, semantic checks, ...
- The resulting tool is completely independent of the target programming language. In our earlier grammars, actions had to be written in a specific programming language such as C. If you wanted to port your grammar to another language, you had to rewrite the actions. With schemas, the "actions" for creating the tree are written as abstract rules, so we can generate syntax functions from them in any language we want. It is very easy and natural to translate an object-oriented schema with syntax rules, into a source file containing classes and node factory functions, written in any modern programming language such as C++, C#, Java, Python, Ruby, JavaScript or PHP.